
What is Fuzzy Matching?
Understanding advanced entity matching

Data Gator
BaseCap's resident data expert
Entity Matching vs Fuzzy Matching
Do all of your spreadsheets and data tables use the same language?
Often, enterprise teams must compare records that are written with different codes or formatting. For example, one list of clients may not include the account number. Or, the names may be recorded as [last, first] rather than [first, last].
These variations can often bring operations to a halt as QA teams try to sort and compare divergent lists.
That’s where entity and fuzzy matching come into play.
Entity matching
The ability to link records that have the same data in real life, but different spelling or formatting between data sets.
Fuzzy matching
The technique or algorithms used to make entity matching possible.
Fuzzy matching techniques, like those employed by the BaseCap platform, speed up operations by quickly identifying and comparing like records.
Entity Matching vs Fuzzy Matching
Entity matching is the ability to link records that have the same data in real life, but different spelling or formatting between data sets. Fuzzy matching is the technique or algorithms used to make entity matching possible.
Matching Records with a Primary Key
Usually, records can be linked by using a shared unique identifier or primary key. Let’s look at how a primary key helps you link records and why linking records is important.
In this example, the primary key is the account number, which helps connect the values in the name column with the correct values in the balance column.
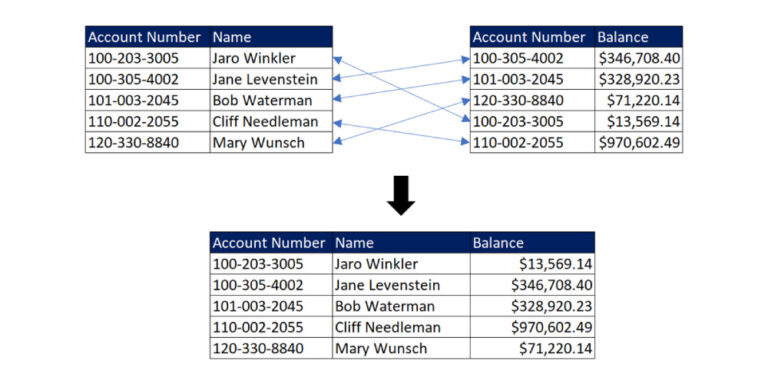
For this case, a simple query can link and merge the two tables into one. This type of basic data management can be useful for performing analysis and generating reports.
When You Need Entity Matching
Often, a primary key is not available, or other factors prevent an accurate match through simple queries.
Let’s look at another example. Here, a mortgage lender is conducting due diligence on credit risk. The respondents did not provide an account number, and the names are spelled differently in each table. Some of these spelling differences are typos, while others are a legitimate variation of a name.
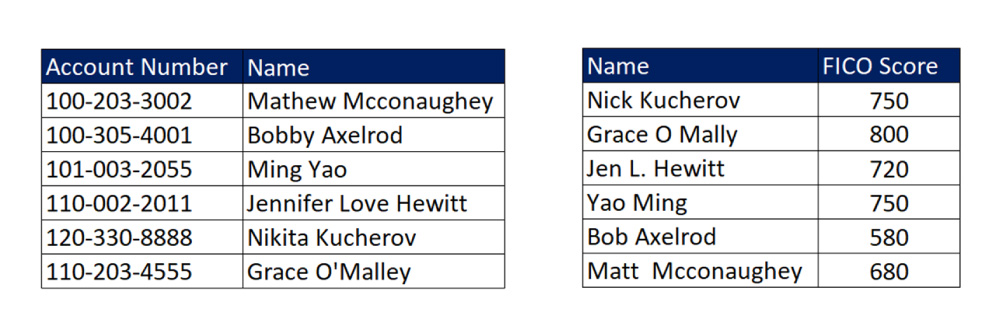
A simple query will not be able to join these two queries because:
- The second table does not have the “Account Number” field as a primary key to link the two tables.
- The “Name” field contains different values, and the two tables share no matching values to link them.
While we (humans) can recognize that Yao Ming and Ming Yao are very likely the same person, the computer doesn’t have this intuition or ability to assess the likelihood of a match without some instructions. This is where the entity matching algorithms become important – to teach the computer to match names that are not identical.
This is where the entity matching algorithms become important: to teach the computer to match names that are not identical.
Now, imagine many more variations across thousands of records that involve phone numbers, addresses, ID numbers, and other key fields. The potential for inaccuracies compounds.
What kinds of data require fuzzy matching?
Some data types require advanced entity matching more than others. Here are some common fields that rely on fuzzy matching for data cleaning.
- Names: Different spellings of the same name is one of the most common reasons for fuzzy matching. A sales rep could have made a mistake during data entry. Or, a data extraction technique like Optical Character Recognition (OCR) could have misread some characters in the name. And it’s not just peoples’ names that create issues. Business names and locations are just as likely to be mispelled.
E.g. “McCafe” vs. “McCafé” and “Mississipi” vs. “Mississippi”
- Addresses: Businesses structure addresses in many different ways. Abbreviations like “Street” vs “St.” or divergent comma usage often throws errors when addresses are reconciled. Consider how this address, “50-50 First Street, Fort Totten Boulevard, 11358,” differs from this address: “50-50 1st St. Ft Totten Blvd, 11358.” These permutations add up quickly when processing hundreds or thousands of names and addresses.
- Phone Numbers: Think about all the times you’re asked to submit your phone number on an online form. The format is always different! Consider +1(234)4567890 vs. 234-456-7890. Matching these records is no easy task for a computer, which makes fuzzy matching an indispensable resource.
Entity / Fuzzy Matching Use Cases
Fuzzy matching enables the linking of records when you don’t have a primary key and identifiers vary between files. Enterprises often use fuzzy matching for the following use cases:
- Combining Data Views: fuzzy matching helps merge tables with different data points to create a view that will provide more insight.
- Removing Duplicate Data: a salesperson may move a name from a prospect list to a current client list but forget to remove the name from the prospect list. Fuzzy matching helps identify duplicates for swift deletion.
- Enhancing Data Extraction: techniques like OCR and Natural Language Processing (NLP) help businesses extract data from PDFs or handwritten notes. As advanced as these processes have become, they still lead to many errors. Fuzzy matching can help cross-reference extracted language against a dictionary to ensure the process produces a real word with correct spelling.
TLDR
Fuzzy matching is an advanced technique to link data points that are connected in real life. Enterprises use fuzzy matching to speed up data comparison and standardization. When combined with a robust data validation process, fuzzy matching helps improve overall data health.
Thanks for reading!
Sign up for new content about data observability, automation, and more.
About BaseCap
BaseCap is the intuitive data validation platform that operations teams use to feed quality data to AI algorithms.
"I think the tool is great because it's an out of the box solution where you can give a business admin, or someone that's knowledgeable enough from a tech perspective and a business perspective, to really drive and make the changes and really own the administration of the tool."
Jeff Dodson, Lument





